Just seeing what time was the last update to an RSS feed should be enough for most. And the RSS feeds already have titles, so one might not need a full OPML, but nothing more than a list of URLs as a flat file.
Although what follows has some room for improvement, feed reading can look like this
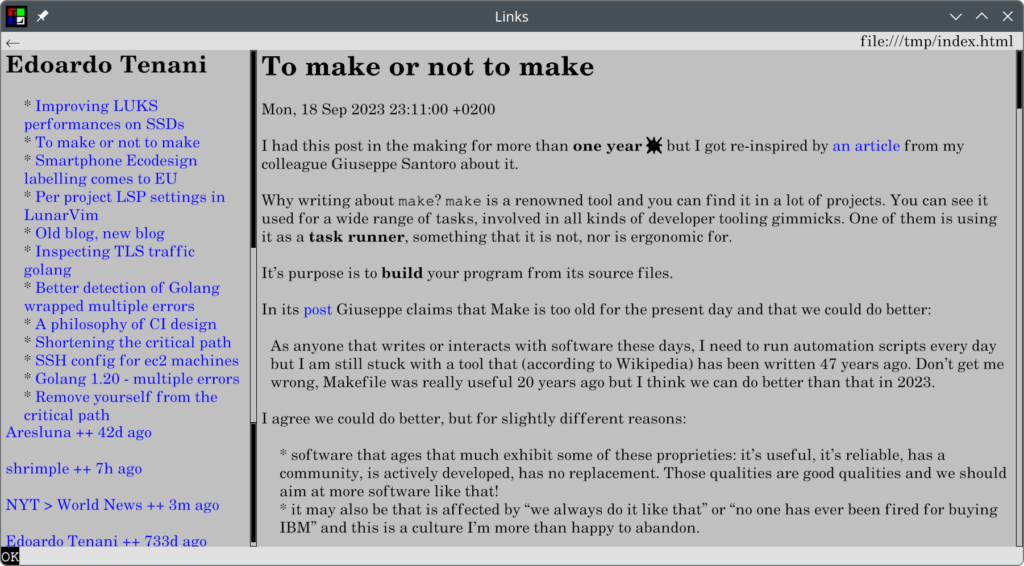
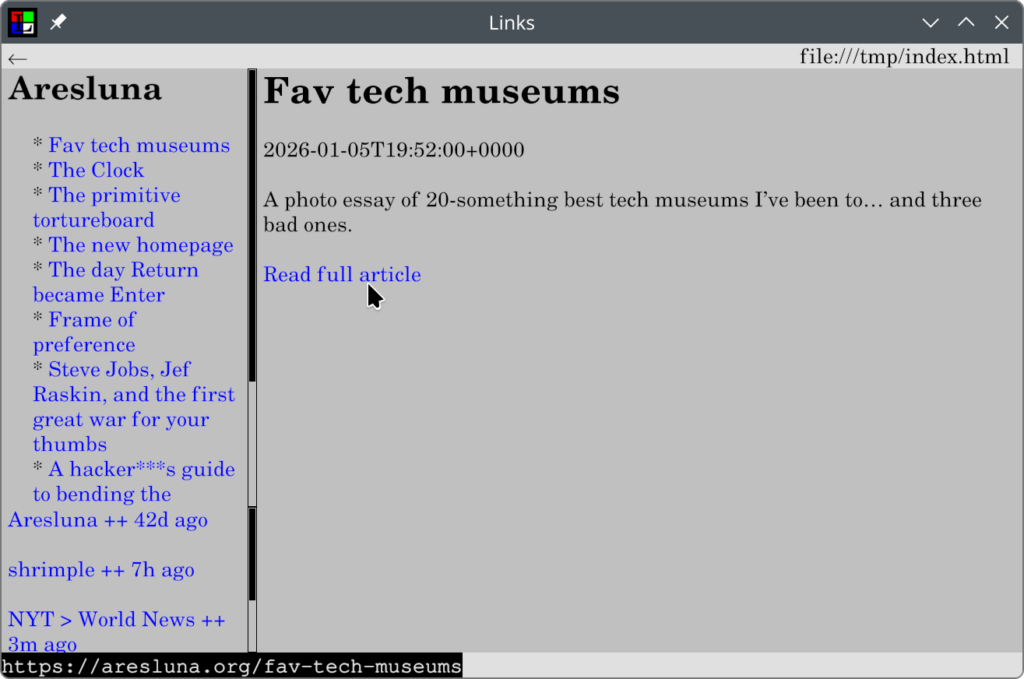
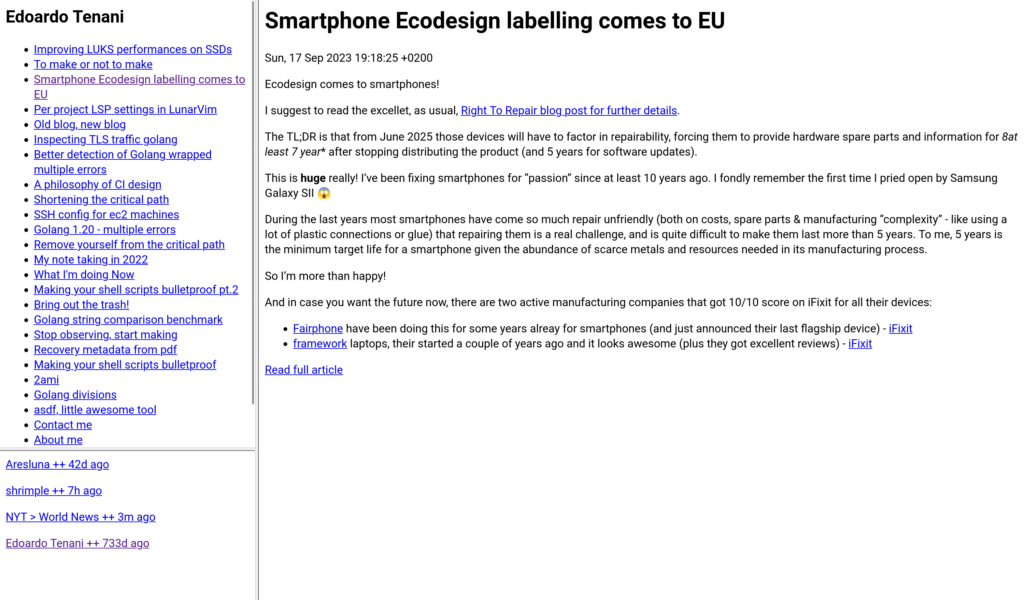
My idea consists of two programs, for potential composability and to not bother with any kind of PATH:
- one gets spawned in a directory and lays out the articles from the feed XML passed to it on standard input,
- and one gets passed a list of feed URLs on standard input, and an argument with the path to the former script (it is not hardcoded to be composed with just that first one, although expects from the provided one not just the nav.html that it will link but also a title.txt and a date.txt in the directory after its execution) — and it creates the index.html with the frameset (constant content) and a feeds.html with the list of feeds and when were they last updated
#!/usr/bin/env perl
use v5.36;
use strict;
use warnings;
use XML::LibXML;
use File::Path qw(make_path);
my $dom = XML::LibXML->load_xml(IO => \*STDIN);
my $xc = XML::LibXML::XPathContext->new($dom);
$xc->registerNs(atom => 'http://www.w3.org/2005/Atom');
sub safe_id ($id, $fallback) {
my $base = ($id && $id =~ /\S/) ? $id : $fallback;
$base =~ s/[^A-Za-z0-9._-]/_/g;
return $base;
}
sub text_of ($node, $xpath) {
my ($n) = $xc->findnodes($xpath, $node);
return defined $n ? $n->textContent : undef;
}
sub write_file ($path, $content) {
open my $fh, '>:encoding(UTF-8)', $path
or die "Cannot write $path: $!";
print $fh $content;
close $fh;
}
# ---
my @entries;
if ($xc->exists('/rss/channel/item')) {
@entries = $xc->findnodes('/rss/channel/item');
}
else {
@entries = $xc->findnodes('/atom:feed/atom:entry');
}
my $feed_title =
text_of($dom, '/rss/channel/title')
// text_of($dom, '/atom:feed/atom:title')
// 'Feed';
my $feed_date =
text_of($dom, '/rss/channel/lastBuildDate')
// text_of($dom, '/atom:feed/atom:updated');
write_file('title.txt', $feed_title);
write_file('date.txt', $feed_date);
# ---
my $nav = "<html><head><title>$feed_title</title></head><body>";
$nav .= "<h2>$feed_title</h2><ul>";
for my $i (0 .. $#entries) {
my $e = $entries[$i];
my $raw_id =
text_of($e, './guid')
// text_of($e, './atom:id');
my $id = safe_id($raw_id, "entry-" . ($i + 1));
my $title =
text_of($e, './title')
// text_of($e, './atom:title')
// 'Untitled';
$nav .= qq{<li><a target="main" href="$id.html">$title</a></li>};
}
$nav .= "</ul></body></html>";
write_file('nav.html', $nav);
# ---
for my $i (0 .. $#entries) {
my $e = $entries[$i];
my $raw_id =
text_of($e, './guid')
// text_of($e, './atom:id');
my $id = safe_id($raw_id, "entry-" . ($i + 1));
my $title =
text_of($e, './title')
// text_of($e, './atom:title')
// 'Untitled';
my $date =
text_of($e, './pubDate')
// text_of($e, './atom:updated')
// text_of($e, './atom:published')
// '';
my $body =
text_of($e, './description')
// text_of($e, './atom:summary')
// text_of($e, './atom:content')
// '';
my $url =
text_of($e, './link')
// text_of($e, './atom:link[@rel="alternate"]/@href')
// text_of($e, './atom:link[1]/@href');
my $html = <<"HTML";
<html>
<head><title>$title</title></head>
<body>
<h1>$title</h1>
<p>$date</p>
<p>$body</p>
HTML
if ($url) {
$html .= qq{<p><a target="_top" href="$url">Read full article</a></p>};
}
$html .= "</body></html>";
write_file("$id.html", $html);
}
say "Done.";
#!/usr/bin/env perl
use v5.36;
use strict;
use warnings;
use String::Util 'trim';
use File::Path qw(make_path);
use IPC::Run qw(start);
sub write_file ($path, $content) {
open my $fh, '>:encoding(UTF-8)', $path
or die "Cannot write $path: $!";
print $fh $content;
close $fh;
}
write_file('index.html', <<"HTML");
<html>
<frameset cols="25%,75%">
<frameset rows="75%,25%">
<frame name="nav"/>
<frame src="feeds.html" name="feeds"/>
</frameset>
<frame name="main"/>
</frameset>
</html>
HTML
use Cwd 'abs_path';
my $workprog = abs_path $ARGV[0];
my @jobs;
my @urls;
while (<STDIN>) {
chomp;
my $dir = $_;
$dir =~ s/[^A-Za-z0-9._-]/_/g;
make_path($dir);
push @urls, $_;
push @jobs, start(
[ qw/curl -sL/, $_ ],
"|",
[ $workprog ],
init => sub { chdir $dir });
}
use Time::Piece;
use Time::Seconds;
sub parse_date ($s) {
for (
"%Y-%m-%dT%H:%M:%S%z",
"%a, %d %b %Y %H:%M:%S %z",
"%Y-%m-%dT%H:%M%z",
) {
$s =~ s/([+-]\d\d):(\d\d)/$1$2/;
my $t = eval { Time::Piece->strptime($s, $_) };
return $t if $t;
}
return;
}
sub human ($t) {
my $d = gmtime() - $t;
$d < ONE_HOUR ? int($d->minutes)."m ago" :
$d < ONE_DAY ? int($d->hours)."h ago" :
int($d->days)."d ago";
}
open my $fh, '>:encoding(UTF-8)', 'feeds.html'
or die "cannot write feeds.html: $!";
use Path::Tiny;
for (@jobs) {
$_->finish;
$_ = shift @urls;
s/[^A-Za-z0-9._-]/_/g;
my $title = path("$_/title.txt")->slurp_utf8;
$title =~ s/[\p{Cf}\p{Mn}\p{So}\p{Sk}]//g;
$title = substr($title, 0, 20);
$title = trim $title;
my $date = path("$_/date.txt")->slurp_utf8;
$date = parse_date $date;
$date = human $date;
print {$fh} <<"HTML";
<p><a href="$_/nav.html" target=nav>$title ++ $date</a>
HTML
}
close $fh;You execute them by running the second one with the path to the first one as an argument (~/feeds_many.pl ~/feeds_one.pl < ~/feeds), and redirect a list of bare URLs as lines to it — it creates you the directory structure and the HTML files; you then navigate with your browser to the index.html, which you of course can do all in a single shell command line.
Run once, read some, run once the next day again.
So, I hope to use it from now on 🙂 and read feeds at last.
In my simplistic ideas, I nonetheless may have been influenced by the approach of Offpunk browser. https://offpunk.net
@shrimple works on my akkoma
Remote Reply
Original Comment URL
Your Profile
Why do I need to enter my profile?
This site is part of the ⁂ open social web, a network of interconnected social platforms (like Mastodon, Pixelfed, Friendica, and others). Unlike centralized social media, your account lives on a platform of your choice, and you can interact with people across different platforms.
By entering your profile, we can send you to your account where you can complete this action.